自生成式AI爆火已有两年,而近期进展似乎不尽人意,大模型鲜有突破性创新,应用层面也未出现杀手级应用,资本市场对“泡沫论”和估值过高争议不断……人们仿佛对AI已经“祛魅”,AI发展真的变慢了吗?
在质疑和期待声中,周五“AI领头羊”OpenAI发布了一个名为MLE-bench的基准测试,专门用来测试ai agent的机器学习工程能力,建立起一个衡量大模型机器学习能力的行业标准。
而这一标准的建立正是在o1亮相之后,上月OpenAI甩出一记重大更新,推理能力超越人类博士水平的o1系列模型面世,实现大模型在推理能力上的一次飞跃。
测试结果显示,在MLE-bench的基准测试下,o1-preview在16.9%的竞赛中获得了奖牌,几乎是第二名(GPT-4o,8.7%)的两倍,是Meta Llama3.1 405b的5倍,也是claude 3.5的2倍。
o1模型还代表了大模型领域新范式的突破——开启推理阶段新Scaling Law。
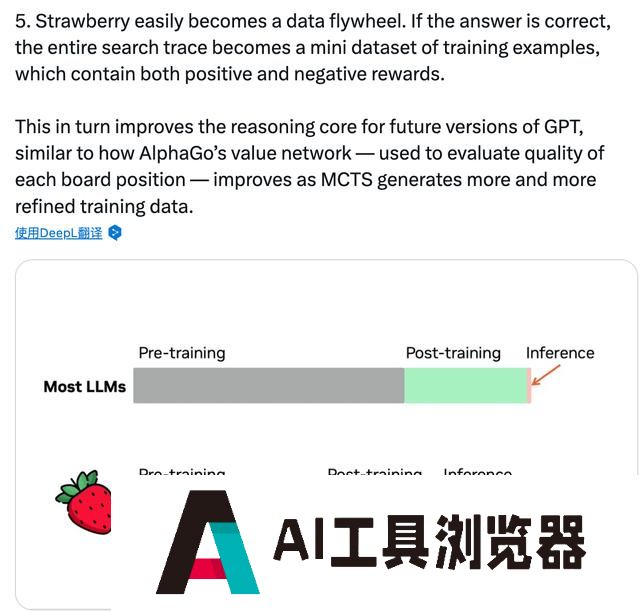
AI领域的Scaling Law(缩放定律)规则,一般是指随着参数量、数据量和算力的增加,大模型的性能能够不断提高。然而,毕竟数据是有限的,AI出现越训练越傻的迹象,Pre-Training(预训练)带来的scaling up边际收益开始递减。
o1在很大程度上突破这一瓶颈,通过post training(后训练)的方式,增加推理过程和思考时间,同样明显提升了模型性能。
相对于传统的预训练阶段scaling Law,o1开启推理阶段新Scaling Law,即模型推理时间越长,推理效果会更好。随着o1开启大模型领域范式创新,会引领AI领域研究重点的转向,行业从“卷参数”迈入“卷推理时间”的阶段,MLE-bench的基准测试正体现了这一衡量标准的转变。
随着大模型推理性能飞跃,芯片算力能力也将相应地升级,黄仁勋在9月的T-Mobile大会上,直接预告算力提速50倍,把o1模型的响应时间从几分钟缩短到几秒:
最近,Sam提出了一个观点,这些AI的推理能力将变得更加聪明,但这需要更多的算力。目前,在ChatGPT中的每个提示都是一个路径,未来将在内部有数百个路径。它将进行推理,进行强化学习,试图为你创造更好的答案。
这就是为什么在我们的Blackwell架构将推理性能提高了50倍。通过将推理性能提高50倍,那个现在可能需要几分钟来回答特定提示的推理模型,可以在几秒钟内回应。因此这将是一个全新的世界,我对此感到兴奋。
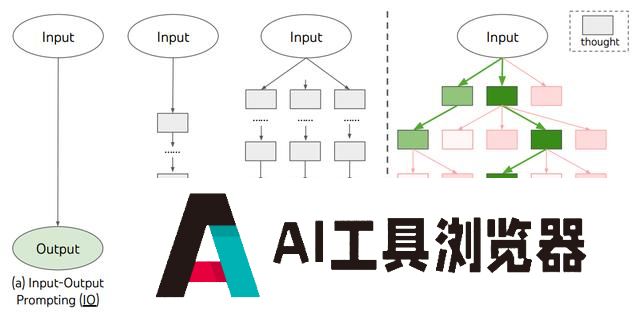
有分析将其类比为《思考,快与慢》里的系统二:
系统一:无意识地快思考,依赖于直觉和经验,快速做出反应,例如刷牙、洗脸等动作。
系统二:深思熟虑,带有逻辑性地慢思考,例如解决数学题或计划长期目标等复杂的问题。
o1模型像是系统二,在回答问题前会进行推理,生成一系列思维链,而之前的大模型更像是系统一。
通过思维链式地拆解问题,在解答复杂问题过程中,模型可以不断验证、纠错,尝试新策略,从而显著提升模型的推理能力。
o1模型另一个核心特征是强化学习,可以进行自主探索、连续决策。正是通过强化学习训练,大模型学会完善自己的思考过程,生成思维链。
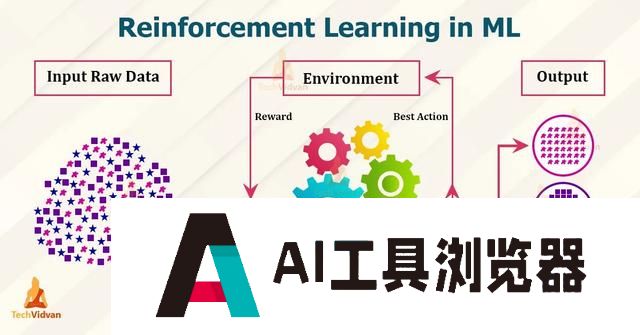
强化学习在大模型中的应用,是指智能体学习在环境中采取行动,并根据行动结果获得反馈(试错和奖励机制),从而不断优化策略。而之前的大模型预训练采用的是自监督学习范式,通常是设计一种预测任务,利用数据本身的信息训练模型。
简而言之,以前的大模型是学习数据,o1更像是在学习思维。
通过强化学习和思维链的方式,o1不仅在量化的推理指标上有了显著提升,在定性的推理可解释性上也有了明显改善。
不过,o1模型只是在特定任务上取得了突破,在文本生成等偏文科向领域并不具备优势,而且o1只是将人的思维过程展现出来,尚不具备真正的人类思考和思维能力。






